LoRA 的广泛应用领域
天使圈子 在疯狂应用loRA工具 规模不小 不亚于16年的小高潮
你们如果会操作loRA这是可以直接切入 电商 医院 法律 各行业的垂直领域的 但是这种模式 有点偏大众
就是大模型结合细分这条路线
以下是 LoRA 在不同模型类型和任务中的应用:
1. 大型语言模型 (LLMs) – 文本生成与理解 ✅
这是 LoRA 最早和最重要的应用领域之一。它可以用来微调像 GPT、LLaMA、ChatGLM 这样的模型。
- 任务举例:
- 指令跟随:让通用大模型学会遵循特定格式的指令(如扮演一个客服助手、一个编程导师)。
- 领域适配:让模型精通某个垂直领域(如法律、医疗、金融),使用该领域的专业术语和知识进行问答和文本生成。
- 代码生成:专门微调模型,使其更擅长生成某种编程语言(如 Python、Solidity)或框架的代码。
- 优势:相比于全量微调,用 LoRA 微调一个几十亿参数的模型,可能只需要一张消费级显卡(如 24G 的 RTX 4090)即可完成,成本极低。
2. 多模态模型 – 结合文本与图像 ✅
一些模型同时处理文本和图像,LoRA 同样可以微调它们。
- 任务举例:
- 图像描述:微调模型,使其能生成更符合特定风格或包含特定术语的图像描述。
- 视觉问答:让模型更擅长回答关于特定领域图像的问题(如医学影像分析、工业质检图片)。
3. 语音与音频模型 ✅
LoRA 也可以应用于语音识别、语音合成或音乐生成模型。
- 任务举例:
- 音色克隆:用少量目标说话人的音频数据微调 TTS 模型,使其能合成出该说话人声音的语音,而无需重新训练整个巨型 TTS 模型。
- 音乐风格化:让音乐生成模型学会生成特定风格(如爵士乐、电子游戏背景音乐)的片段。
4. 扩散模型(Stable Diffusion 等) – 这就是你熟悉的图片领域 ✅
这就是 LoRA 最“出圈”的应用,但它只是 LoRA 能力的冰山一角。
- 任务举例:
- 学习特定人物、物体、画风、风格、构图等。
5. 其他序列模型 ✅
理论上,任何包含大型线性层的模型都可以用 LoRA 来进行高效微调。
LoRA 在不同领域的对比
| 领域 | 模型示例 | 微调目标 | 优势 |
|---|---|---|---|
| 大型语言模型 | LLaMA, GPT, ChatGLM | 指令遵循、角色扮演、领域知识 | 极大降低计算门槛,让个人开发者也能微调大模型 |
| 文生图模型 | Stable Diffusion, SDXL | 特定人物、风格、物体 | 文件小巧(几MB),组合方便,训练快 |
| 多模态模型 | BLIP, Flamingo | 图像描述、视觉问答 | 高效适配特定视觉-语言任务 |
| 语音模型 | VITS, WaveNet | 音色克隆、情感语调 | 用少量数据实现声音的个性化定制 |
💡 为什么你会觉得 LoRA 只适合图片?
这主要是因为:
- 社区热度:Stable Diffusion 及其衍生应用拥有极其庞大和活跃的开源社区。无数爱好者都在训练和分享各种有趣的 LoRA 模型(人物、画风等),这使得 LoRA 在 AI 绘画领域的可见度最高。
- 直观的成果:图片生成的成果非常直观和吸引人,一个几MB的 LoRA 文件就能显著改变输出结果,这种“魔力”很容易传播和引起讨论。
- 技术传播路径:很多用户是通过 Stable Diffusion WebUI 等工具第一次接触并使用了 LoRA 功能,因此自然地将 LoRA 与图片生成划上了等号。
💎 总结
LoRA 是一种强大的、通用的参数高效微调技术,而绝非仅限于图片领域。
它的核心价值在于:极大地降低了大型模型个性化适配的门槛,让研究者、开发者和爱好者能够用有限的算力资源(一张好的显卡)来定制化那些原本需要巨大成本才能微调的模型。
所以,无论是在 文本、语音、代码 还是 图片 领域,只要你面对的是一个参数巨量的大模型,并且想让它快速学会一件新事情,LoRA 通常都是一个非常值得优先尝试的微调方案。
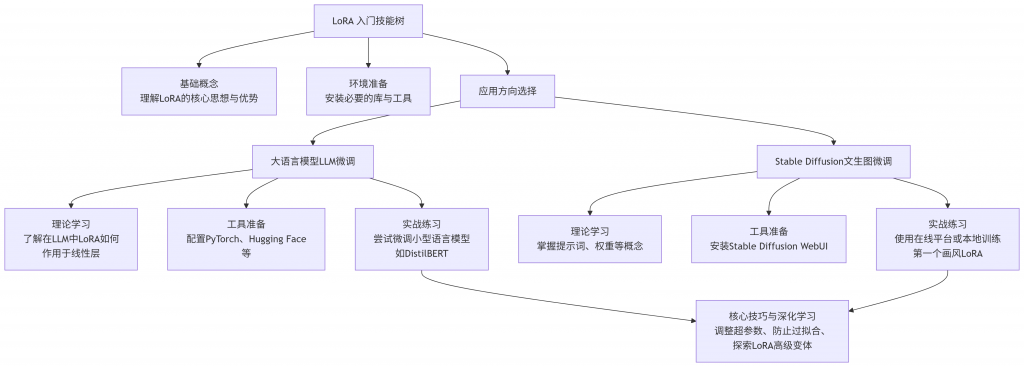
掌握基础概念
首先需要理解 LoRA 的核心思想:不对原始大模型的所有参数进行微调,而是只优化新增的、参数量很少的低秩矩阵,用这些矩阵来“适配”或“指导”大模型完成新任务。这样做的好处非常明显:
- 计算效率高:需要训练和存储的参数大大减少,一张消费级显卡(如 RTX 4090)就可能完成微调。
- 效果不错:在许多任务上,其性能可以媲美全参数微调。
- 灵活便携:训练得到的 LoRA 权重文件通常很小(从几 MB 到一两百 MB),便于分享和切换。
🔧 选择工具与环境准备
根据你想应用的方向,准备相应的工具和环境:
- 对于大语言模型 (LLM) 微调:
- 对于 Stable Diffusion 文生图微调:
🧪 从实践开始
理论学习之后,一定要动手实践。
- 对于 LLM 微调:可以从小模型和经典数据集入手。例如,参考 Sebastian Raschka 的教程,尝试用 LoRA 微调 DistilBERT 模型在 IMDb 电影评论分类数据集上的表现。教程中显示,使用 LoRA 方法在测试准确率上达到了 92.39%,优于仅微调模型最后几层的方法(86.22% 的测试准确率)。
- 对于文生图微调:
🚀 掌握核心技巧与深化学习
入门后,下面这些技巧能帮你做得更好:
- 超参数调整:
rank(秩)值是一个关键的超参数。更高的rank意味着更强的表现力但也可能增加过拟合风险,需要尝试找到最佳配置。 - 避免过拟合:如果模型只在训练数据上表现好,泛化能力差,可能是过拟合了。增加数据多样性、使用正则化技术或调整学习率可能有帮助。
- 探索更多可能性:
⚠️ 留意常见问题
- “灾难性遗忘” (Catastrophic Forgetting):指模型在学习新任务后,丧失了对原有知识的掌握。LoRA 由于其方法特性,在一定程度上有助于缓解这个问题,但仍需注意。
- LoRA 模型与基础模型的匹配:使用 LoRA 时,配套的大模型效果更好。例如,用于训练 LoRA 的底模与生成时使用的大模型如果一致或相近,效果通常更可预测。
- 触发词 (Trigger Words):一些 LoRA 模型(尤其是人物类)可能需要在提示词中使用特定的触发词才能激发出最佳效果。
希望这些信息能助你在 LoRA 的学习道路上顺利起步。
16条评论
https://instrumen.unmuhjember.ac.id/universitas/slot/
Such a great job updating the process.
balcony safety nets in hydarabad
Bu konu hakkında bilgi vermeniz çok güzel. Genellikle türkçe içerikler az oluyor fakat böyle güzel içerikler görmek ve okumak çok zevkli.
Cornelius Gottlieb
Your articles never fail to captivate me. Each one is a testament to your expertise and dedication to your craft. Thank you for sharing your wisdom with the world.
perde
You’re so awesome! I don’t believe I have read a single thing like that before. So great to find someone with some original thoughts on this topic. Really.. thank you for starting this up. This website is something that is needed on the internet, someone with a little originality!
CLOUD STORAGE
Rainx Drive is the Best Cloud Storage Platform
Annalise Gutierrez
çok başarılı ve kaliteli bir makale olmuş güzellik sırlarım olarak teşekkür ederiz.
tuzla escort
Nice post. I learn something totally new and challenging on websites
kartal escort
Good post! We will be linking to this particularly great post on our site. Keep up the great writing
pendik escort
This was beautiful Admin. Thank you for your reflections.
buddy app
I recommend trying Buddy, the new social media platform.
đồng hồ đếm ngược
哈,这篇LoRA科普写得真是出圈啊!果然图片生成最吸睛,但看完才知它只是冰山一角,文本、语音都能玩?这技术简直是给普通用户开了挂,用张破显卡就能定制大模型,性价比拉满!不过社区热度太高,大家都以为LoRA只会画美少女和像素风,就像以为AI只会写代码和画画一样天真(?)。总之,LoRA这万能钥匙得赶紧学起来,不然被别人用着调戏各种模型,自己只能干瞪眼了!😄💪hẹn giờ online
safari planning guide
Romantic Getaways to Consider for Summer 2025
Warren Frost
Pretty! This has been a really wonderful post. Many thanks for providing these details.
Dylan Hendrix
I appreciate the balanced view — you didn’t oversell the solution.
Theresa Fry
This is my first time pay a quick visit at here and i am really happy to read everthing at one place
黑贝
哇哇哇哇